1. Introduction
Le service healthdata.be (Sciensano) traite chaque rapport d'incident selon une procédure opérationnelle standard (Standard Operating Procedure - SOP). Une version publique de cette SOP « HD Incident Management Process » est également disponible sur ce portail : docs.healthdata.be. Vous trouverez ci-dessous la description de la procédure (instructions de travail).
2. Procédure
2.1. Diagramme
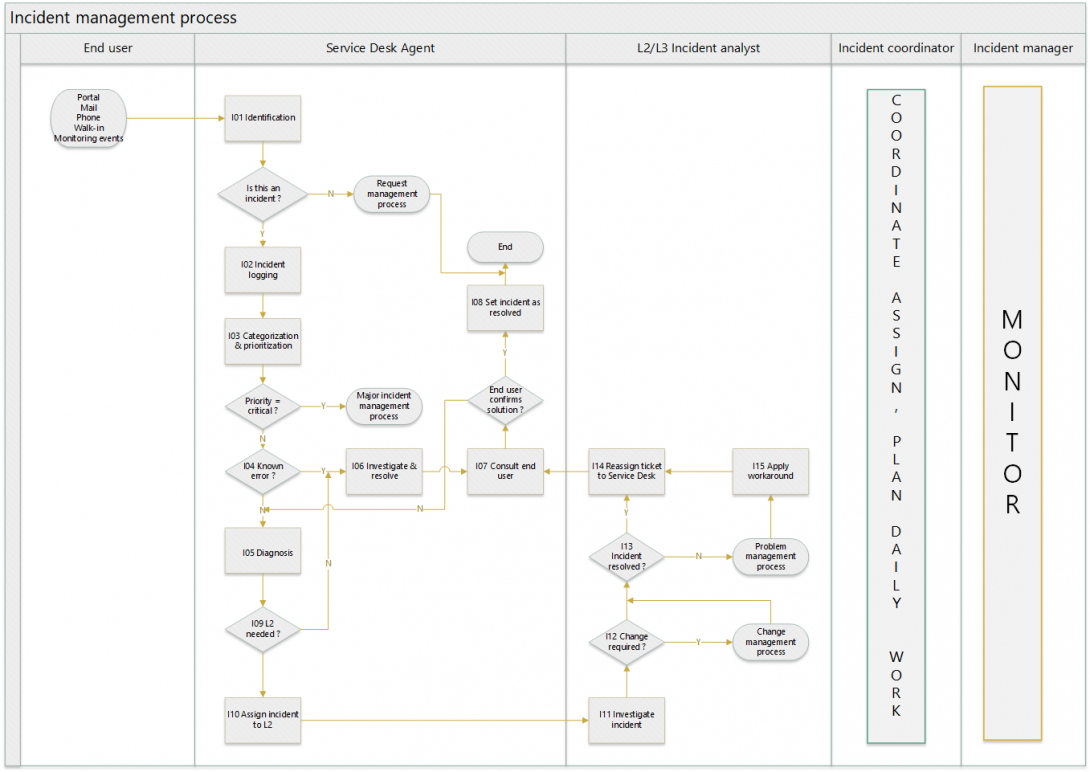
2.2. Instructions de travail
2.2.1. ÉTAPE 1. Identification
Action :
L'utilisateur final peut déclencher un incident par ces moyens :
- Portail : moyen privilégié de signaler un incident.
- E-mail : un utilisateur envoie un e-mail à l'adresse support.Healthdata@sciensano.be. Le Service Desk a un jour pour le prendre en compte et créer un ticket au nom de cet utilisateur (= appelant sur la page).
- Téléphone : un utilisateur contacte le Service Desk par téléphone pour signaler un incident. Le Service Desk créera immédiatement, pendant qu'il est au téléphone, un ticket au nom de cet utilisateur (= appelant sur la page).
- En personne : un utilisateur peut se rendre physiquement au Service Desk pour signaler un incident. Le Service Desk créera immédiatement un ticket au nom de cet utilisateur (= appelant sur la page).
- Suivi d'évènement : une alerte ou un événement peut déclencher la création automatique d'un incident.
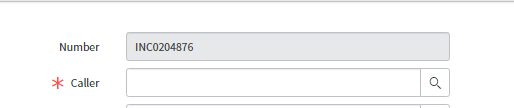
Si l'utilisateur n'existe pas, le Service Desk créera d'abord l'utilisateur et continuera de créer l'incident.
Tapez « user » (utilisateur) dans la barre de recherche, et choisissez « user » dans la liste.
Remplir : « User ID » : adresse e-mail de l'utilisateur.
2.2.2. ÉTAPE 2. Enregistrement d'un incident
Action : Le Service Desk effectuera une première analyse du ticket d'incident. Si le ticket d'incident :
- n'est pas un incident, mais une demande : le ticket d'incident sera fermé et le Service Desk créera une demande de service.
- est un incident : le ticket sera enrichi de la première analyse.
Champs à remplir en cas d'appel, d'envoi d'e-mail ou de visite d'un utilisateur :
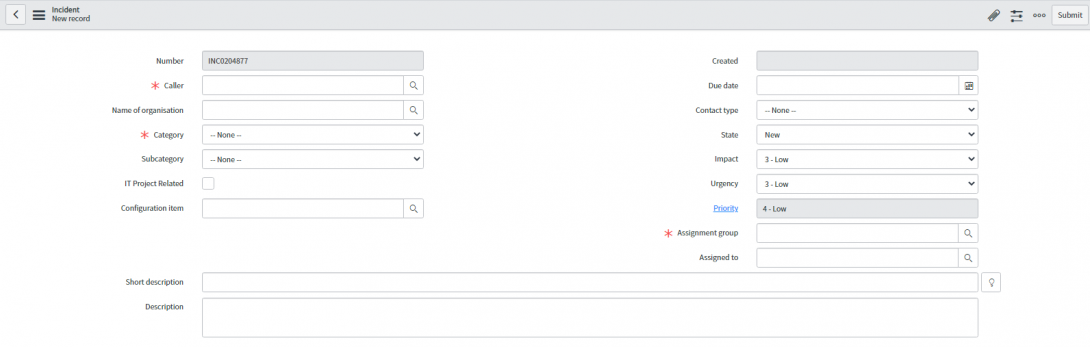
Les champs avec un « * » sont des champs obligatoires :
- Appelant : le nom de l'utilisateur qui veut enregistrer l'incident (voir étape 1 Identification).
- Catégorie : choisir la bonne catégorie sur laquelle l'incident a été détecté :

- Groupe d'attribution : au départ, le ticket est toujours assigné au groupe d'attribution du Service Desk « healthdata.be Service Desk ».
Autres champs :
- Le champ « Assigned to » (Assigné à) est rempli par le coordinateur d'incident du groupe d'attribution. Il décide qui est le plus apte à résoudre l'incident et qui est disponible.
- La description succincte décrit en quelques mots l'objet de l'incident.
- La description est très importante pour l'analyse de l'incident et doit être aussi complète que possible.
- Une fois que tous les champs sont remplis et que l'incident est soumis, il n'est plus possible de modifier aucun champ, à l'exception du groupe d'attribution. Toutes les informations relatives au travail doivent être notées dans les « Work notes » (Notes de travail). Le champ « Customer communication » (Communication avec le client) est également visible pour les utilisateurs finaux dans le portail.
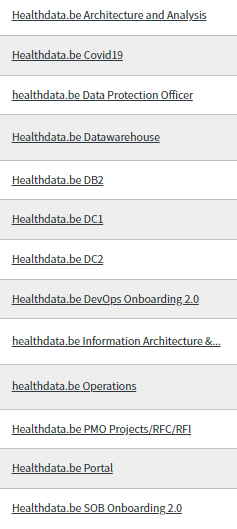
- Les autres groupes d'attribution (groupes de niveau 2) sont :
2.2.3. ÉTAPE 3. Catégorisation
Action : Le Service Desk vérifiera ou modifiera la catégorie pour laquelle l'incident a été ouvert :
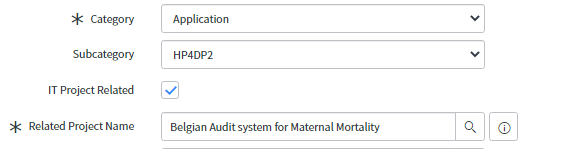
Choisissez la catégorie et la sous-catégorie dans une liste déroulante. Si la description de l'incident comprend un projet (DCD), cochez la case « IT Project Related » (Projet lié à l'IT) et choisissez le projet dans la liste.
2.2.4. ÉTAPE 3(1). Établissement des priorités
Action : Le Service Desk vérifiera ou modifiera la priorité sur laquelle l'incident a été ouvert :
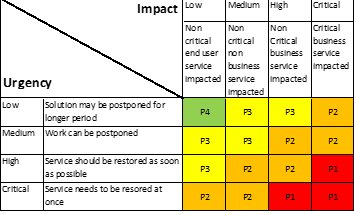
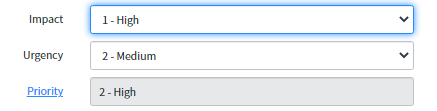
Si l'utilisateur (l'appelant) n'est pas satisfait de la priorité, il peut demander au Service Desk de la modifier. Toutefois, seul un gestionnaire d'incidents ou un COORD peut décider de porter un incident au niveau P1.
2.2.5. ÉTAPE 4. Erreur connue
Action : Le Service Desk va essayer de détecter si une solution est déjà connue dans la base de connaissances ou dans un registre de problèmes. Si elle est trouvée, le Service Desk appliquera cette solution.
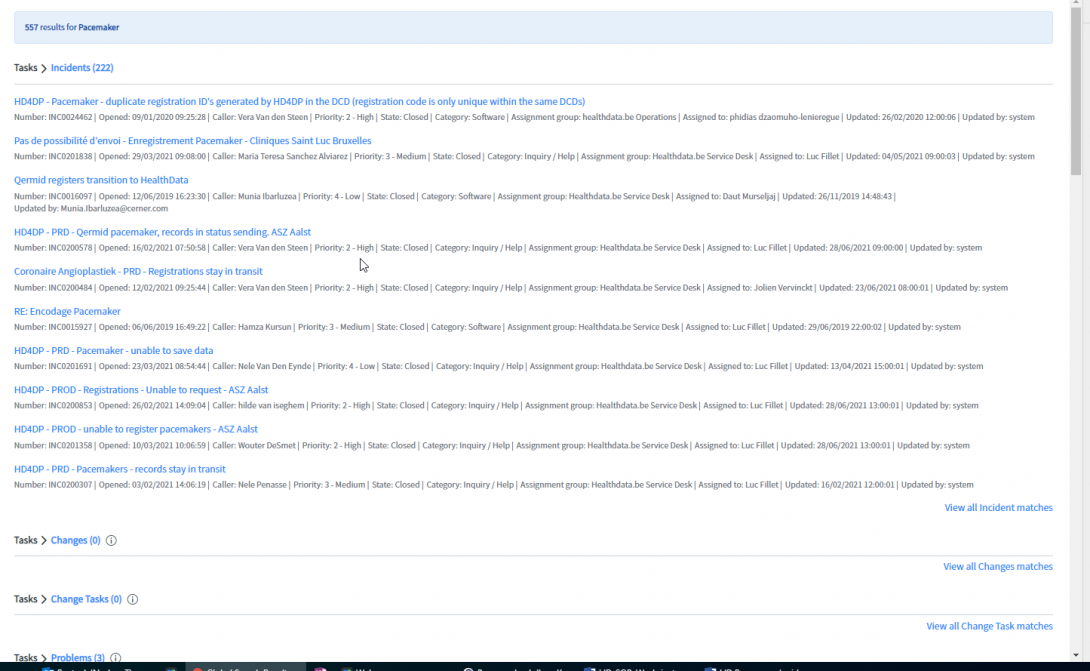
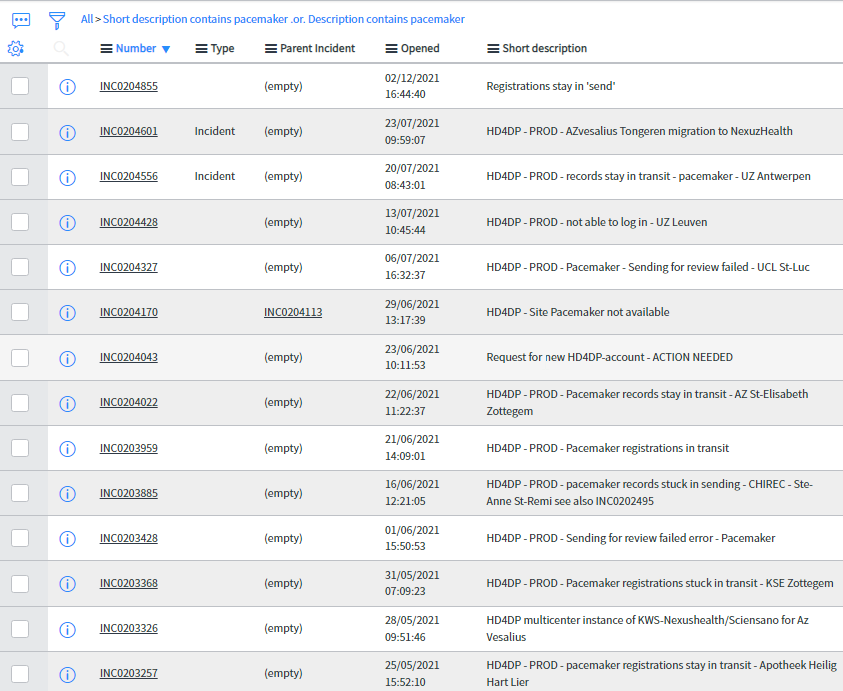
- Un mot clé peut être saisi dans la barre de recherche (par exemple « Pacemaker »). Le résultat sera affiché, pour tous les processus.
- Un filtre peut être effectué dans l'écran des incidents.
Cliquez sur l'entonnoir

Le filtre s'ouvrira

Vous pouvez modifier, ajouter, supprimer et définir des filtres à l'aide des fonctions « AND » (ET) et « OR » (OU).

En cliquant sur « run » (exécuter), le filtre sera exécuté et les résultats seront affichés au niveau des incidents :
2.2.6. ÉTAPE 5. Diagnostic
Action : Le diagnostic de l'incident sera effectué après la première analyse (2).
Le Service Desk note le diagnostic dans les « Work notes » ou, si nécessaire, pour informer ou consulter l'utilisateur, dans le champ « Customer Communication ».
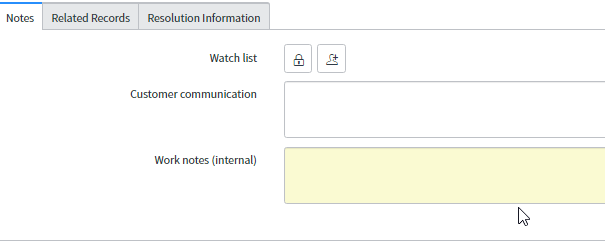
Si l'utilisateur doit être consulté, le Service Desk changera le statut en « On hold » (En attente) et « Awaiting Caller » (En attente de l'appelant).

2.2.7. ÉTAPE 6. Enquêter et résoudre
Action : Une fois que le Service Desk dispose de toutes les informations nécessaires, une enquête peut être menée et une solution appliquée. Le Service Desk va :
- Remplir les notes de résolution dans la langue de l'utilisateur.
- Cliquer sur « Update » (Mettre à jour) (PAS encore sur « Resolve » (Résoudre)).
- Changer le statut en « On hold » et « Awaiting Caller ».

2.2.8. ÉTAPE 7. Consulter l'utilisateur final
Action : Le Service Desk appellera l'utilisateur pour lui demander de valider la solution appliquée. En outre, l'utilisateur recevra une notification dans le portail et par e-mail lui indiquant qu'il doit confirmer la solution appliquée dans les 5 jours. (voir Procédure SOP « Manage Awaiting tickets »).
2.2.9. ÉTAPE 8. Définir l'incident comme résolu
Action : Lorsque l'utilisateur confirme la solution appliquée, le Service Desk :
- Ajoute la confirmation dans les « Work notes »
- Choisit le bon « resolution code » (code de résolution) :
- Dans la plupart des cas : « Solved (permanently) » (Résolu (de façon permanente))
- Au cas où une solution de contournement serait appliquée : « Solved (work around) » (Résolu (solution de contournement))
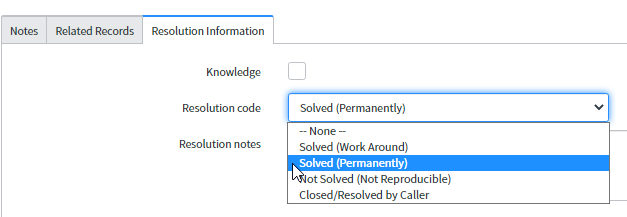
- Cliquez sur « Resolve » (Résoudre)

Une fois que le Service Desk a changé le statut du ticket d'incident en « resolved » (résolu), l'utilisateur final dispose de 5 jours ouvrables pour rouvrir le ticket. Après 5 jours ouvrables, le statut du ticket sera automatiquement passé en « closed » (fermé). L'utilisateur final et le Service Desk ne pourront pas rouvrir le ticket, et devront créer un nouveau ticket d'incident.
2.2.10. ÉTAPE 9. L2 nécessaire ?
Action : Si le Service Desk est capable de résoudre l'incident, le ticket restera dans le groupe et continuera avec l'étape 6. Si le Service Desk ne peut pas résoudre l'incident, le ticket sera assigné au groupe L2.
- Voir l'étape 2 pour une liste des groupes d'attribution.
2.2.11. ÉTAPE 10. Assigner un incident à L2
Action : Une fois que le ticket est assigné à un groupe L2, le coordinateur d'incidents de ce groupe particulier doit gérer ce ticket, sous le contrôle du gestionnaire d'incidents.
2.2.12. ÉTAPE 11. Enquêter sur l'incident
Action : Après l'enquête et le diagnostic du Service Desk, le groupe L2 poursuit l'enquête sur l'incident, avec l'aide éventuelle d'un groupe L3 (partie externe).
Le numéro de ticket du groupe L3 (partie externe) doit être saisi dans le champ « Your ticket number ».

Si le ticket est traité par une tierce partie, le statut du ticket doit être défini comme « On hold » et « Awaiting vendor » (En attente d'un fournisseur).
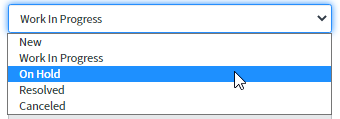
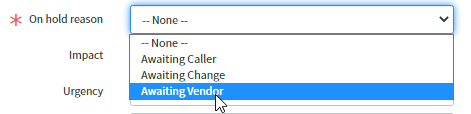
Une fois que la tierce partie a traité le ticket, le statut sera changé en « Work in progress » (Travail en cours) et le travail continuera.
2.2.13. ÉTAPE 12. Changement requis ?
Action : Après une enquête plus approfondie, le groupe L2 doit décider si un changement est nécessaire (fonctionnel ou infrarouge) pour résoudre l'incident.
Si ce n'est pas le cas, l'étape suivante 13 est applicable, et le statut reste « Work in progress ».
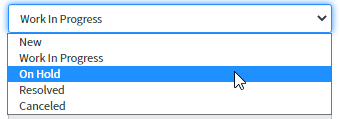
Si oui, le processus de gestion des changements démarre, et le statut est « On hold », « Awaiting change » (En attente de changement).
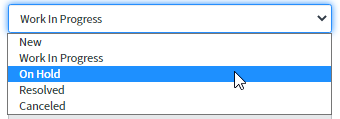

Le numéro de modification sera noté dans l'onglet « Related records » (Dossiers connexes) dans le champ « Change request » (Changer la demande) et le bouton « Update » sera appliqué.

Lorsque la modification a été exécutée, le statut du ticket sera changé en « Work in progress » et le travail continuera.
2.2.14. ÉTAPE 13. Incident résolu ?
Action : Si l'incident est résolu, les notes de travail du ticket d'incident seront mises à jour avec la solution proposée.
Si aucun changement n'est nécessaire, mais que l'incident n'est toujours pas résolu :
- le processus de gestion des problèmes commence
- le statut est défini comme suit : « On hold », « Awaiting problem » (En attente du problème)
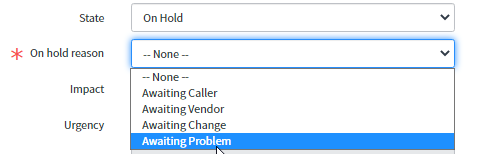
Le numéro du problème sera noté dans l'onglet « Related records », dans le champ « Problem » et le bouton « Update » sera appliqué.

Une solution de contournement doit être trouvée pour résoudre temporairement l'incident.
2.2.15. ÉTAPE 14. Réassigner le ticket au Service Desk
Action : Lorsque la solution (permanente ou par le biais d'une solution de contournement (ÉTAPE 15) est appliquée, le ticket d'incident sera réassigné au Service Desk, qui poursuivra avec l'étape 7.
2.2.16. ÉTAPE 15. Appliquer une solution de contournement
Action : Si l'incident ne peut être résolu de façon permanente :
- Une solution de contournement doit être appliquée pour résoudre temporairement l'incident.
- Le contournement doit être saisi dans les notes de travail du ticket d'incident et dans l'onglet « Analyse » du ticket de problème (voir « Problem management »).
- Le ticket est réassigné au Service Desk (ÉTAPE 7).